TL; DR
- 베이지안 딥러닝은 결과뿐만 아니라 예측 불확실성까지 추론할 수 있다는 장점이 있지만, 동시에 추론 속도가 상당히 느리다는 단점이 있습니다. 우리는 이를 해결하기 위해 기억된 예측을 사용하는 벡터 양자화 베이지안 딥러닝을 제시했습니다.
- 벡터 양자화 베이지안 딥러닝을 데이터 스트림에 적용시키면 뉴럴넷 예측의 시간적 평활화, 또는 지수이동평균을 얻습니다.
- 시간적 평활화는 베이지안 딥러닝의 계산 속도를 수십 배 빠르게 향상시켜줄 뿐만 아니라, 원래의 베이지안 딥러닝과 비슷하거나 때로는 더 나은 수준의 정확도와 불확실성을 예측할 수 있는 구현하기 간편한 방법입니다.
복습: 벡터 양자화 베이지안 딥러닝은 사전에 기억된 예측을 사용해 추론 속도를 향상시킵니다
베이지안 딥러닝(BNN, Bayesian neural network)은 결과뿐만 아니라 불확실성까지 예측할 수 있는 방법입니다. 하지만 우리는 효율적인 추론을 위한 벡터 양자화 베이지안 딥러닝에서 BNN은 추론 속도가 수십 배 느리다는 단점때문에 실용적으로 쓰이기에 많은 제약이 있다는 문제를 제기했습니다. 그리고 이를 해결하기 위해 사전에 기억된 예측을 사용해 추론 속도를 향상시키는 벡터 양자화 베이지안 딥러닝(VQ-BNN, vector quantized Bayesian neural network)을 제안했습니다.
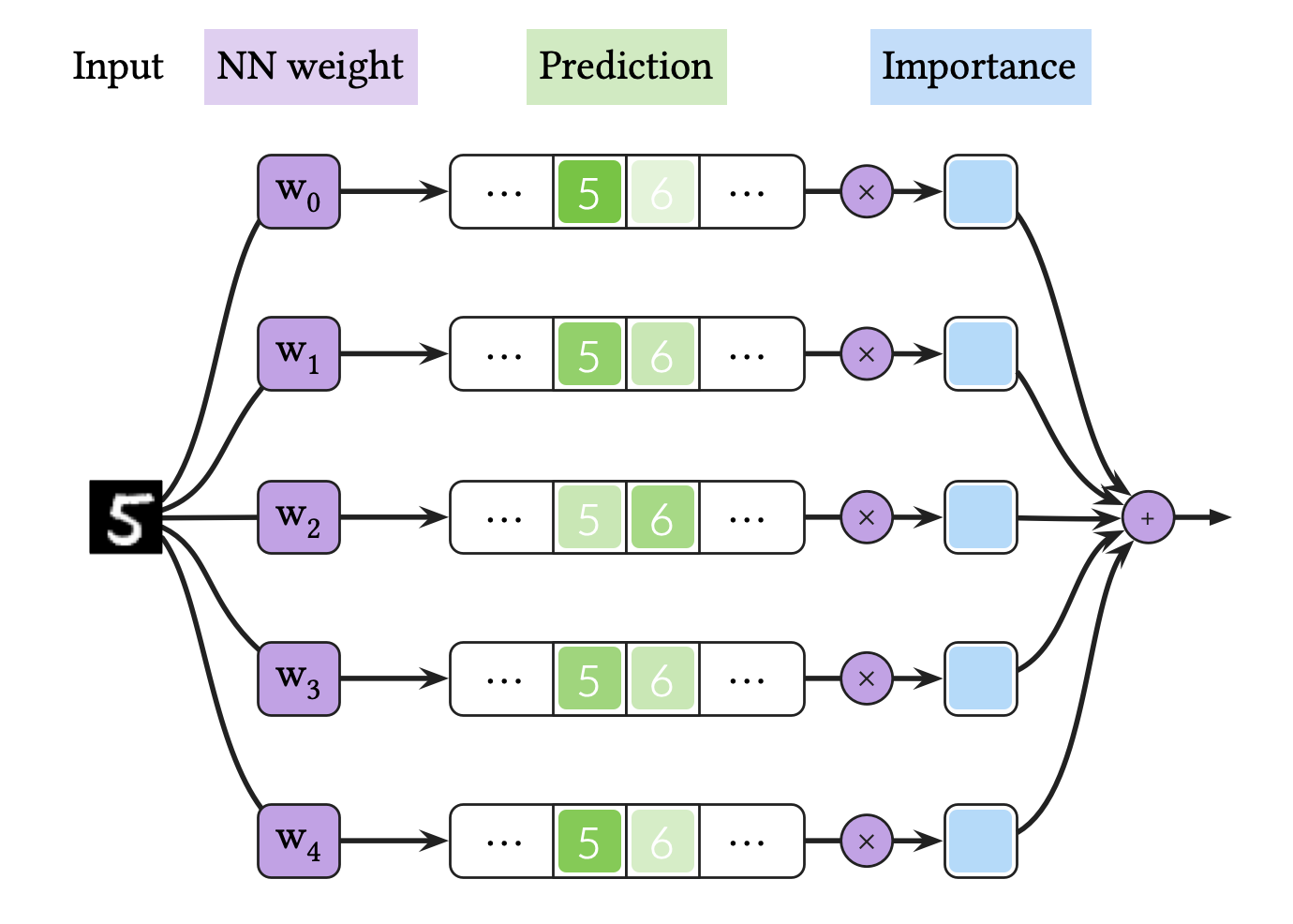
위 그림은 BNN의 추론 과정을 도식화한 것입니다. 즉, BNN 추론은 BNN 모델들의 앙상블 평균이라고 할 수 있습니다. 뉴럴넷을 통해 반복적으로 결과를 예측하는 것은 계산 복잡도가 높으며, 이는 BNN 추론을 느려지게 하는 주요한 원인입니다.
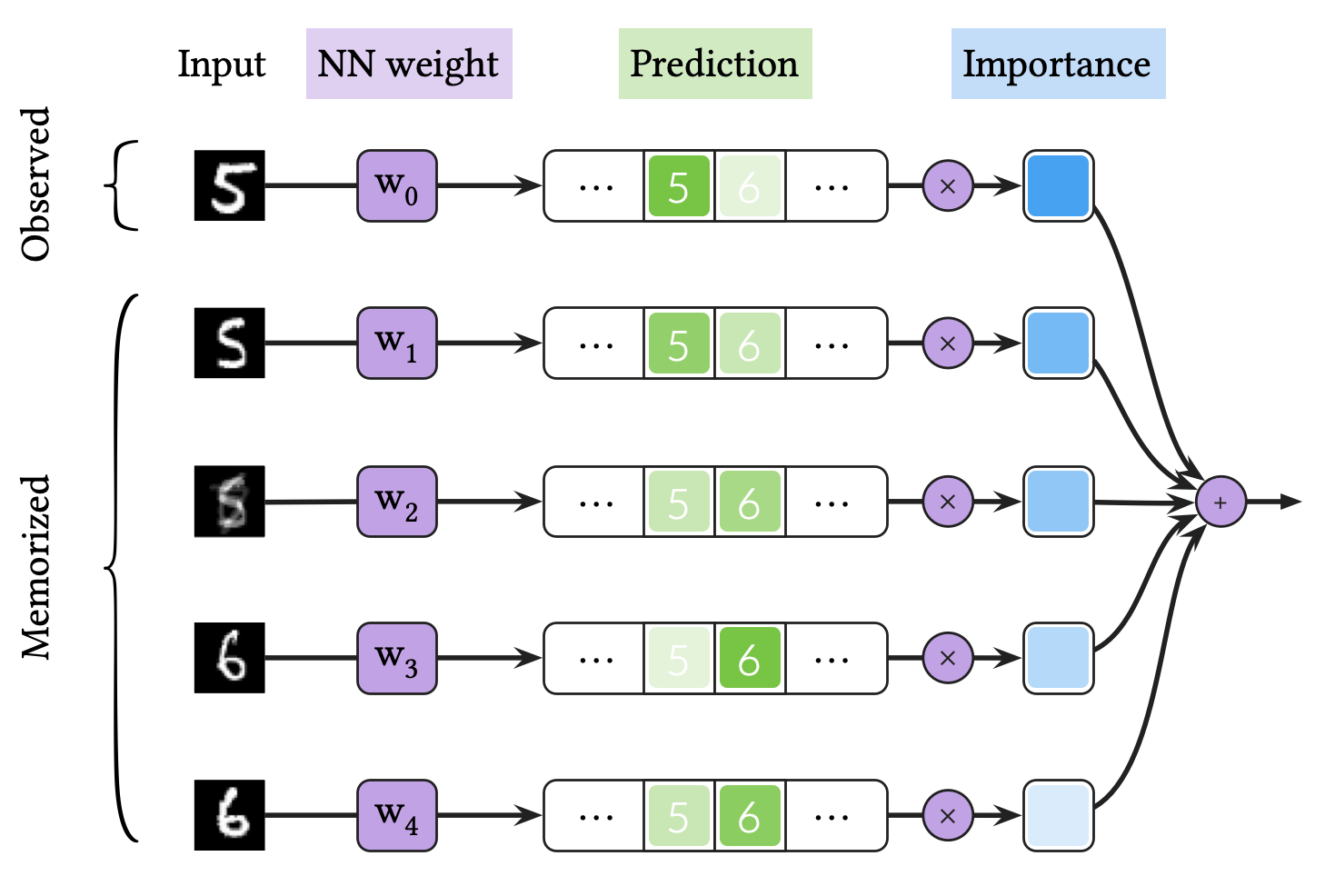
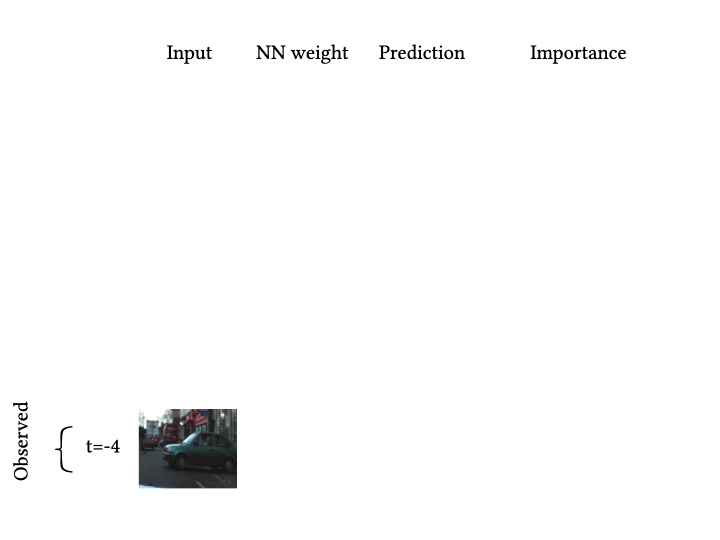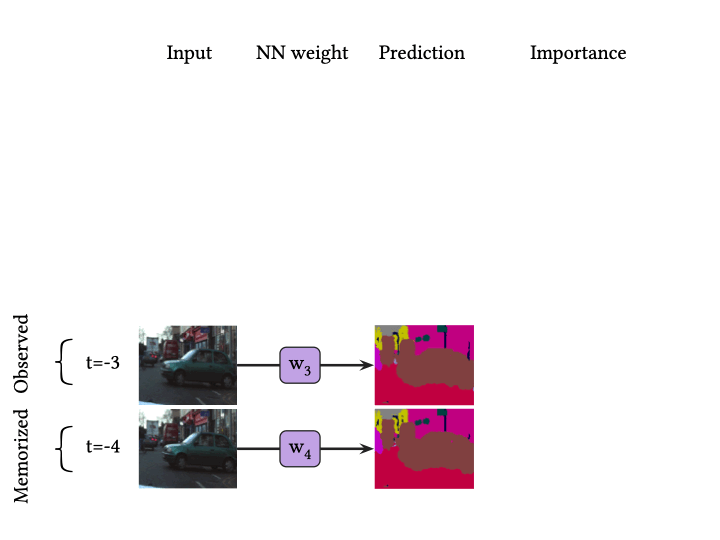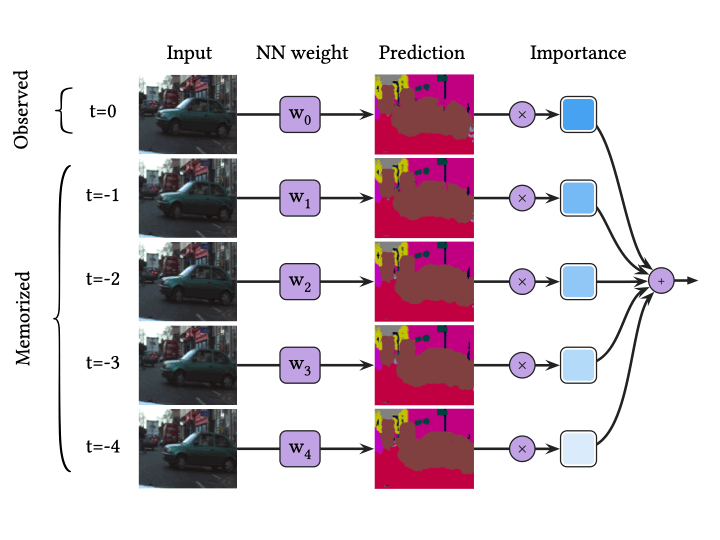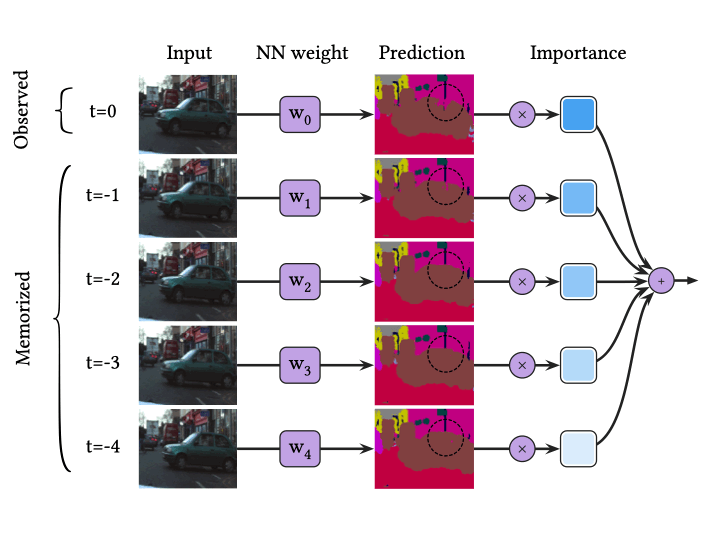
한편, 위 그림은 VQ-BNN 추론 과정을 도식화한 것입니다. VQ-BNN은 BNN과 달리 관측 데이터에 대해 한 번만 예측을 추론하는 대신, 사전에 기억된 예측을 사용해 이를 보완합니다. 이때, 기억된 예측이 얼마만큼의 중요도(importance)로 결과에 반영될지는 관측된 데이터와 기억된 데이터 (프로토타입) 사이의 유사도를 기반으로 결정합니다. VQ-BNN은 이 과정에서 뉴럴넷을 사용해 예측을 단 한 번만 추론하기 때문에, 효율적으로 결과를 계산할 수 있습니다.
VQ-BNN 추론을 실제로 적용시키기 위해서는 어떤 프로토타입을 기억할 것인지, 중요도를 어떻게 정할 것인지 결정해야 합니다. 이때, 프로토타입과 중요도는 계산 효율성을 위해 다음과 같은 조건을 만족해야 합니다.
- 프로토타입: 가능한 관측 데이터와 비슷한 데이터로 구성되어야 합니다.
- 중요도: 계산 복잡도가 높지 않아야 합니다.
데이터 스트림 분석, 특히 동영상에 대한 데이터 처리는 추론 속도가 중요한 분야입니다. 동영상은 용량이 크며, 때때로 실시간 처리를 요구할 수도 있습니다. 따라서, 추론 속도가 느린 BNN을 동영상 처리에 접목하는 것은 실용적이지 않은 것처럼 보입니다. 대신 우리는 이 포스트에서 VQ-BNN을 이용해 쉽고 효율적으로 동영상을 처리할 수 있음을 보일 것입니다.
실제 세계의 데이터 스트림은 시간에 따라 연속적으로 변합니다
우리는 VQ-BNN을 데이터 스트림에 적용하기 위해 실제 세계의 데이터 스트림의 일반적인 성질을 사용할 것입니다. 즉, 비디오와 같은 데이터 스트림은 시간에 따라 연속적으로 변하는 성질이 있습니다. 이것을 데이터 스트림의 시간적 일관성(temporal consistency) 또는 시간적 유사성(temporal proximity)이라고 부릅니다.
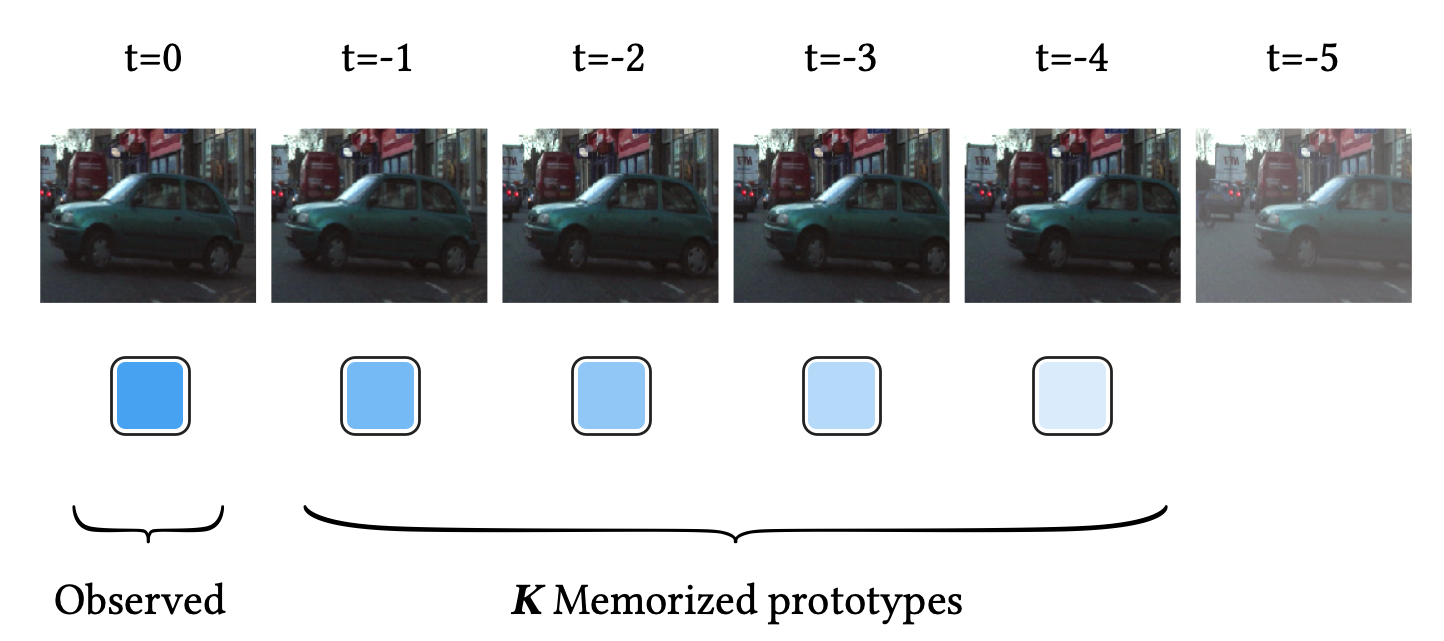
위 그림은 비디오의 시간적 일관성에 대한 한 가지 예시를 보여줍니다. 이 비디오 스트림에서 자동차는 timestamp 가 증가할수록 천천히 오른쪽에서 왼쪽으로 연속적으로 움직이고 있습니다. 여기서 가장 최근의 프레임 $t=0$을 관측 데이터라고 하겠습니다.
데이터 스트림의 시간적 일관성 덕분에, 우리는 최근 개의 프레임을 프로토타입 로 삼음으로써 관측 데이터와 비슷한 프로토타입을 다음과 같이 구성할 수 있습니다.
이와 유사하게, 우리는 관측 데이터와 프로토타입 사이의 유사도(즉, 프로토타입의 중요도)를 시간이 지날수록 지수적으로 감소하도록 정할 수 있습니다.
여기서 는 감소율을 결정하는 hyperparameter입니다. 분모는 중요도의 합을 1로 만들어주기 위한 정규화 상수(normalizing constant)입니다.
이 둘을 사용하면, VQ-BNN 추론은 시간 에서 뉴럴넷이 예측하는 확률 의 시간에 대한 평활화(temporal smoothing) 또는 뉴럴넷 예측에 대한 지수이동평균(EMA, exponential moving average)로 주어집니다.
여기서 는 정규화 상수입니다.
이와 같은 프로토타입과 중요도를 사용해 실제로 다음과 같이 구현할 수 있습니다. 분류 문제에 대해 뉴럴넷이 예측하는 확률 은 흔히 Softmax를 이용해 구할 수 있습니다.
여기서 은 시간 에서의 뉴럴넷 로짓(logit)입니다.
Semantic segmentation에 시간적 평활화 적용하기
우리는 앞서 데이터 스트림에 대한 VQ-BNN은 뉴럴넷 예측의 시간적 평활화라는 것을 보였습니다. 이제 이 시간적 평활화를 실제 세계의 문제에 적용시켜보겠습니다. 우리는 아래의 예제에서 BNN을 구현하기 위해 MC dropout을 사용하겠습니다.

Semantic segmentation은 픽셀 단위의 이미지 분류 문제입니다. 위 그림은 BNN을 사용한 semantic segmentation을 묘사하고 있습니다. MC dropout을 BNN으로 사용한다면, 위 그림은 하나의 비디오 프레임에 대해 5번 결과를 예측해 서로 다른 픽셀별 (Argmax가 아닌) Softmax 확률 분포를 계산한 뒤, 이를 평균하는 과정을 묘사하고 있습니다. 충분한 예측 성능을 달성하기 위해 일반적으로 30번 결과를 예측해야 하며, 따라서 이 과정은 한 번 뉴럴넷을 수행하는 것에 비해 30배 느려집니다.
한편 BNN은 추론 과정에서 하나의 프레임만을 사용하며, 이 입력 데이터에 크게 의존하는 성질을 갖고 있습니다. 입력은 때때로 모션 블러나 비디오 디포커스와 같은 이유로 비정상적인 데이터를 포함할 수 있으며, 이때 BNN은 잘못된 결과를 내놓게 될 수 있습니다. 이 예제에서 점선 동그라미로 표시된 자동차의 창문은 건물과 구분하기 힘든 부분입니다. 따라서, 대부분의 예측이 전부 부정확한 분류 결과를 나타내고 있습니다.
위 그림은 시간적 평활화를 사용한 semantic segmentation을 묘사하고 있습니다. 우리는 매 프레임마다 단 한 번만 결과를 예측합니다. 대신 과거의 예측을 기억하며, 가장 최근의 예측과 과거의 예측을 중요도를 사용해 가중 평균함으로써 최종 결과를 도출합니다. 이 과정은 새로운 비디오 프레임에 대해 단 한 번 예측을 수행하기 때문에, 일반적인 결정론적 뉴럴넷 추론과 비슷한 계산 복잡도를 가집니다.
시간적 평활화는 가장 최근의 예측과 동시에 과거의 예측을 사용하므로, 가장 최근의 예측에 대한 오차를 과거의 예측이 보완해 줍니다. 따라서, 입력이나 입력의 예측이 비정상치(outlier)를 포함하고 있더라도 더욱 강건한 예측을 수행할 수 있습니다. 이 예제에서, 가장 최근 프레임에서의 자동차 창문은 건물과 구분하기 어려운 순간이었습니다. 실제로, 가장 최근의 프레임에 대한 예측은 BNN과 마찬가지로 부정확하게 분류되었습니다. 하지만 과거의 프레임에서 자동차의 창문은 비교적 건물과 구분하기 쉬웠으며, 뉴럴넷은 이를 올바르게 분류했습니다.
정성적 결과
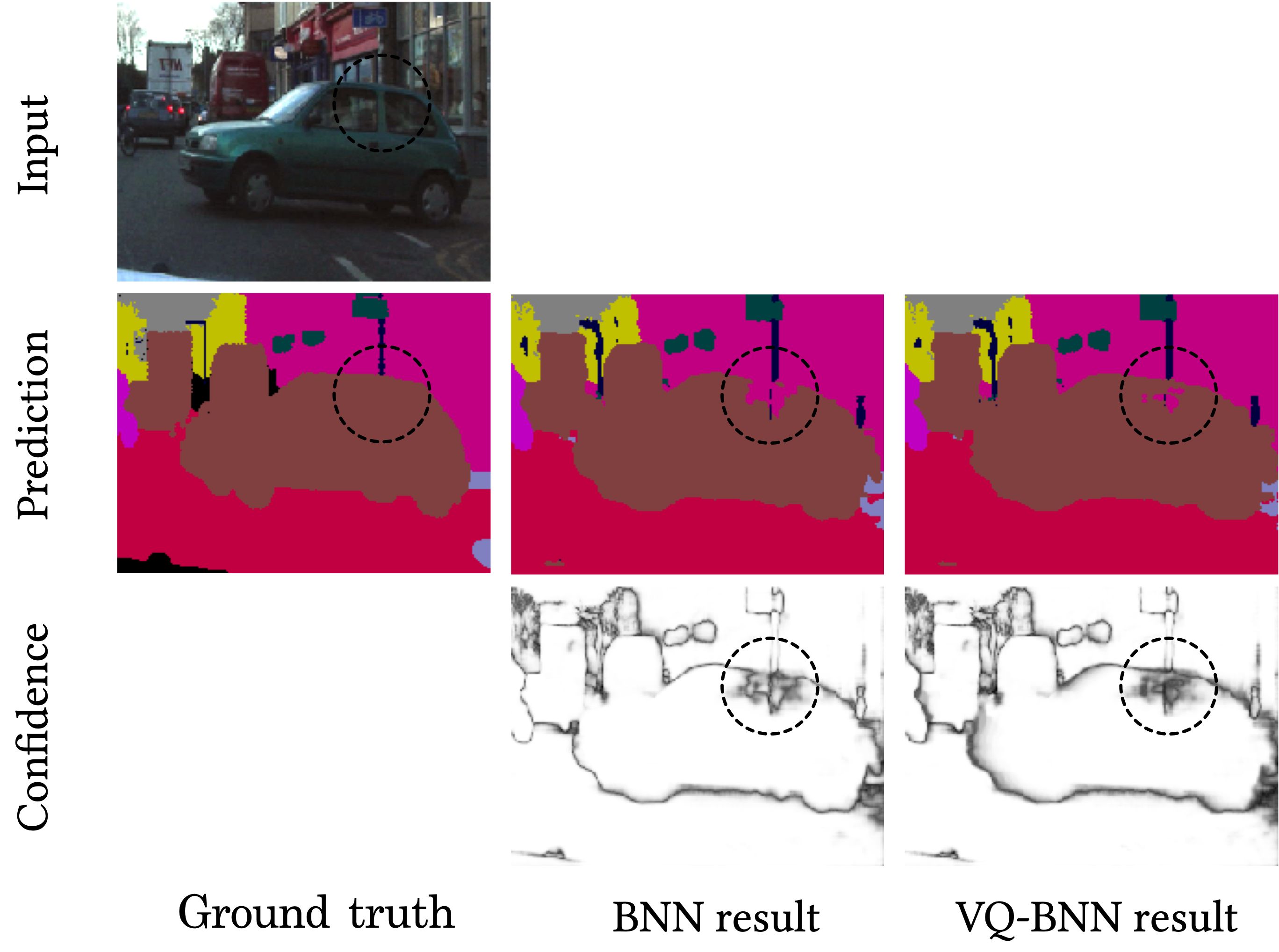
앞선 예제에서의 결과를 확인해 보겠습니다. 위의 그림의 두 번째 줄은 자동차에 대한 semantic segmentation 예제의 분류 결과(예측 확률 분포의 Argmax)를 나타냅니다. 우리가 기대한 대로, BNN은 잘못된 결과를 예측했습니다. 반면, VQ-BNN은 비교적 결과를 정확하게 예측했습니다.
한편 위 그림의 세번째 줄은 신뢰도(예측 확률 분포의 Max)를 나타냅니다. 여기서 더 밝을수록 더 높은 신뢰도를 뜻하며, 더 어두울수록 높은 예측 불확실성을 나타냅니다. 이 그림에서 보듯이 VQ-BNN은 BNN보다 결과를 지나치게 확신하는 경향이 덜합니다. 이는 VQ-BNN이 모델 불확실성뿐만 아니라 데이터에 대한 불확실성까지 동시에 표현하기 때문입니다.

더욱 이해를 돕기 위해, 위와 같은 비디오 시퀀스에 대한 각 방법의 예측 결과 차이를 비교해보겠습니다. 우리는 여기서 일반적인 딥러닝인 결정론적인 딥러닝(DNN, deterministic neural network)과 BNN(MC dropout)을 기준치로 두겠습니다. 그리고 이들을 DNN과 BNN의 시간적 평활화인 VQ-DNN 및 VQ-BNN과 비교하겠습니다.
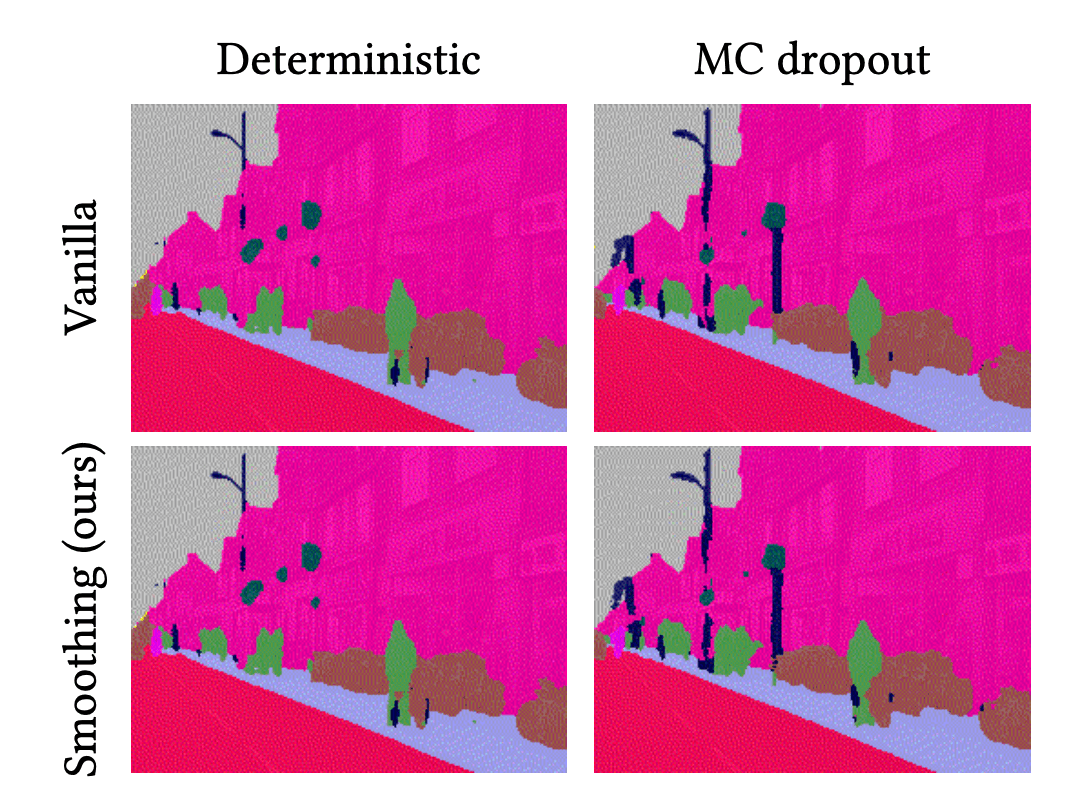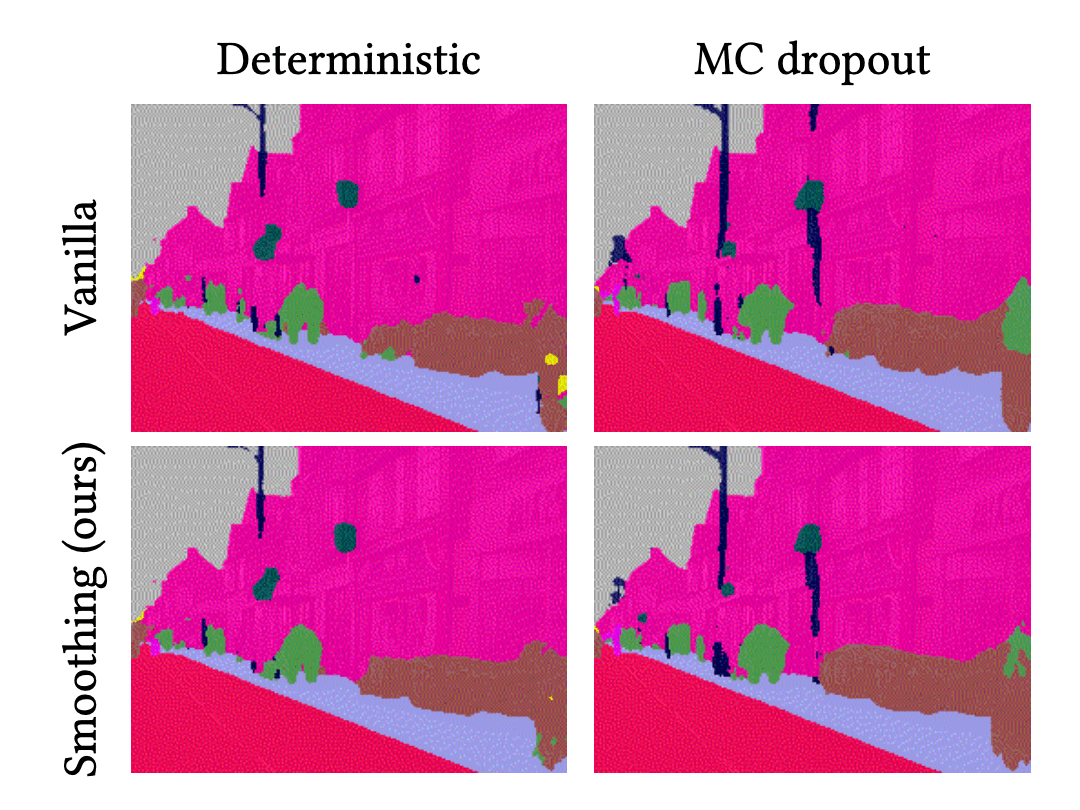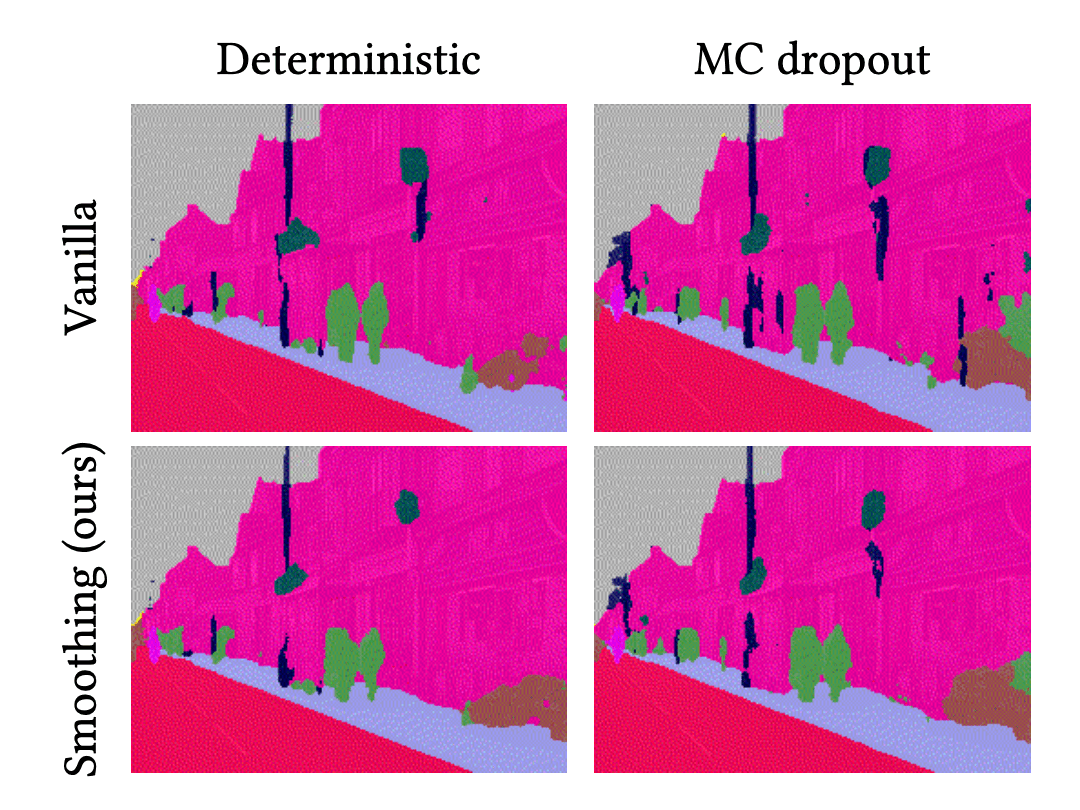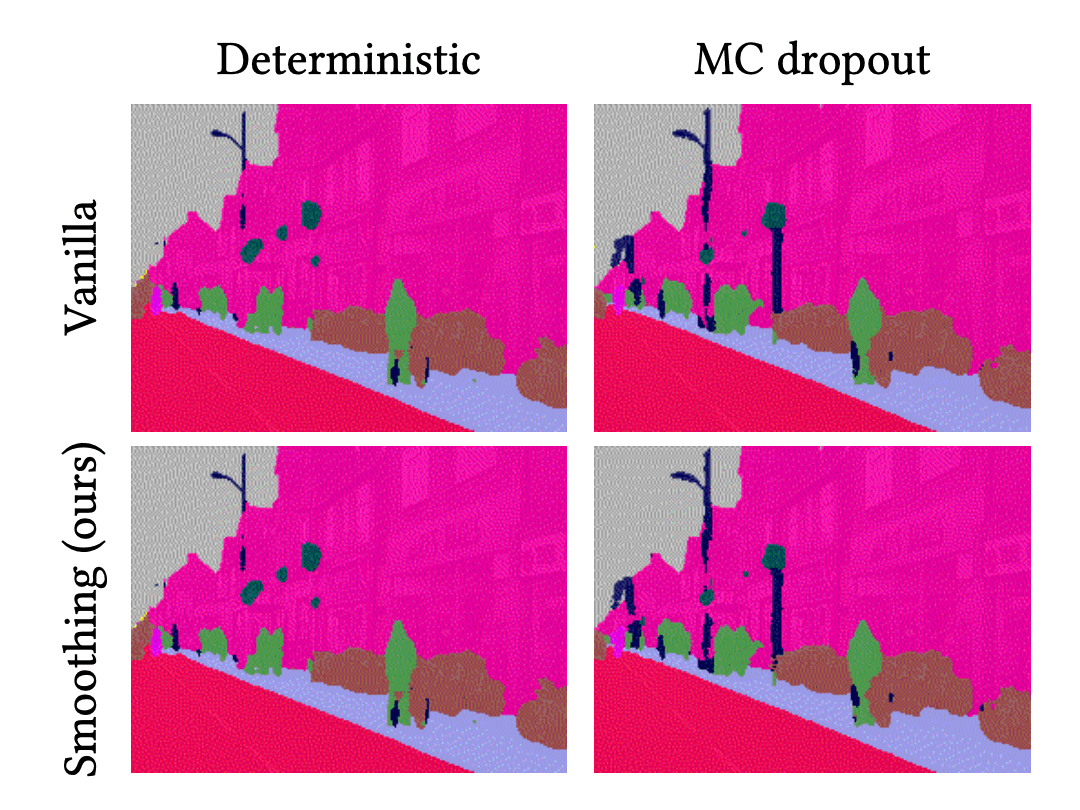
이 애니메이션은 각 방법의 예측 결과를 보여줍니다. 첫번째 줄은 결정론적 딥러닝(DNN)과 BNN의 결과를 나타내며, 두번째 줄은 이들의 시간적 평활화 결과를 나타냅니다.
위와 같은 결과는 DNN과 BNN의 예측 결과는 잡음이 있다는 것을 보여줍니다. 다시 말하면, 이들의 객체에 대한 분류 결과는 불규칙적이고 무작위로 변경됩니다. 실제로 이와 같은 현상은 semantic segmentation뿐만이 아니라 딥러닝을 사용한 이미지 처리에서 전반적으로 나타나는 현상입니다. 예를들어, object detection에서 bounding box의 크기가 부자연스럽게 변경되거나, 없어졌다 생기기기도 하는 것을 상상해 보시기 바랍니다. 반면, 시간적 평활화는 이 잡음을 감소시켜주고 예측 결과를 안정화시키는 역할을 합니다. 위의 결과에서 보듯이, VQ-DNN과 VQ-BNN의 예측 결과는 부드럽게 바뀝니다. 결론적으로, 시간적 평활화는 뉴럴넷의 예측을 좀 더 자연스럽게 하는데 사용될 수도 있을 것입니다.
정량적 결과
우리는 앞서 데이터에 노이즈가 많다면 VQ-BNN이 BNN에 비해 정확한 결과를 낼 수 있을 것이라고 추측했습니다. 아래와 같은 정량적 결과는 이 추측이 맞을 수 있음을 보여줍니다.
| Method | Rel Thr (%, ↑) |
NLL (↓) |
Acc (%, ↑) |
ECE (%, ↓) |
|---|---|---|---|---|
| DNN | 100 | 0.314 | 91.1 | 4.31 |
| BNN | 2.99 | 0.276 | 91.8 | 3.71 |
| VQ-DNN | 98.2 | 0.284 | 91.2 | 3.00 |
| VQ-BNN | 92.7 | 0.253 | 92.0 | 2.24 |
위의 표는 semantic segmentation에서 각 방법의 성능을 보여줍니다. 화살표는 각 지표가 어떤 방향으로 변해야 더 나은지를 나타냅니다.
이 표에서 우리는 각 방법의 추론 속도를 비교하기 위해 초당 비디오 프레임이 몇 장 처리되는지를 측정했습니다. 그리고 DNN을 기준으로 이를 상대적으로 비교한 상대적 처리량(Rel Thr, relative throughput)을 지표로 사용했습니다. 이 실험에서 우리는 30번 뉴럴넷 추론을 반복한 BNN을 사용했기 때문에, BNN의 처리량은 DNN에 비해 1/30배에 불과합니다. 반면, VQ-BNN은 DNN과 유사한 수준의 처리량을 보여주며, BNN보다 30배 빠릅니다.
한편 이 표에서 우리는 각 방법의 예측 성능을 비교하기 위해 negative log-likelihood (NLL), 정확도 (Acc, accuracy), expected calibration error (ECE)를 측정했습니다. 우선, 우리가 기대한 대로 BNN은 DNN보다 더 나은 예측 성능을 보여줍니다. VQ-BNN의 예측 성능은 우리가 기대한 것을 넘어서는 결과를 보여줍니다. VQ-BNN은 DNN보다 나을 뿐만 아니라, BNN보다도 나은 성능을 보여줍니다. 마찬가지로, VQ-DNN의 결과는 BNN을 사용하지 않더라도 시간적 평활화가 예측 성능을 향상시킨다는 것을 보여줍니다.
위의 결과는 BNN으로 MC dropout을 사용해서 얻어졌지만, deep ensemble을 사용하더라도 비슷한 결과를 얻을 수 있습니다. 5개의 서로 다른 모델을 사용했을때 deep ensemble의 NLL은 0.216을 기록했습니다. 한편, 이 deep ensemble에 시간적 평활화를 적용시키면 deep ensemble을 사용한 성능과 비슷한 수준인 0.235의 NLL을 얻을 수 있었습니다.
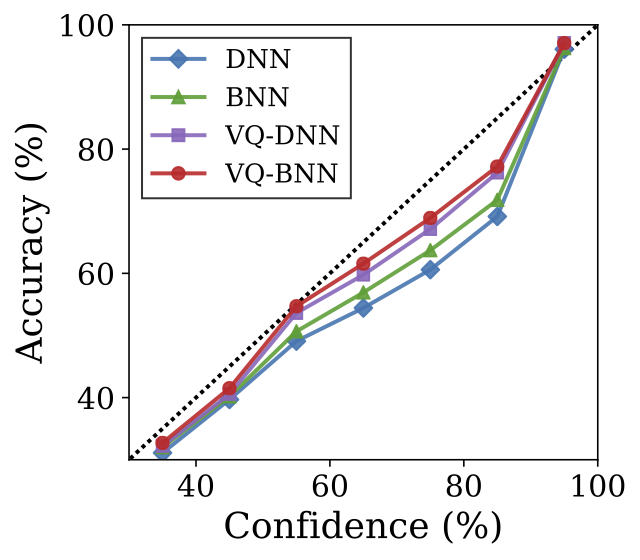
위의 결과는 각 방법에 대한 reliability diagram을 보여줍니다. 위 표와 마찬가지로, 이 그림은 시간적 평활화가 예측 불확실성을 교정(calibration)하는데 유의미한 효과가 있음을 보여줍니다. 이 결과는 DNN은 가장 불확실성이 교정되어있지 않다는 것을 보여줍니다. 반면, VQ-BNN은 DNN은 물론, BNN보다도 더 신뢰할 수 있는 불확실성을 추정한다는 것을 확인할 수 있습니다. 마찬가지로, VQ-DNN도 DNN과 BNN 모두에 비해 더 신뢰할 수 있는 불확실성을 추정하고 있습니다.
결론적으로, 과거로부터 기억된 예측을 사용하는 것은 계산 및 예측 성능을 개선시키고 특히 불확실성을 추정하는데 효과적입니다. 시간적 평활화는 데이터 스트림에서 이전의 예측을 사용하는 구현하기 간편한 방법이며, 예측 성능에 대한 희생 없이 베이지안 딥러닝의 추론 속도를 수십 배 빠르게 향상시키는 기법입니다.
더 읽을거리
- 이 포스트는 논문 “Vector Quantized Bayesian Neural Network Inference for Data Streams”을 기반으로 작성되었습니다. VQ-BNN에 대한 더욱 엄밀하고 자세한 사항은 해당 논문을 참고해주시기 바랍니다. VQ-BNN의 구현은 GitHub을 참고해주시기 바랍니다. 만약 이 포스트나 논문이 유용하다고 생각하신다면, 위 논문을 인용해주시면 감사하겠습니다. 이와 관련된 첨언이나 피드백이 있으시다면, 편하게 연락해 주시기 바랍니다.
- Semantic segmentation에서의 더 많은 정성적인 예시는 GitHub을 참고해 주시기 바랍니다.
- 우리는 과거의 예측뿐만이 아닌 미래의 예측을 사용해 예측 성능을 더욱 향상시킬 수 있다는 것을 보였습니다. 자세한 사항은 논문의 Appendix D.1과 Figure 11을 참고해 주시기 바랍니다.
-
아래는 monochronic depth estimation에서 각 방법이 예측하는 결과와 불확실성의 예를 보여줍니다. 이 예에서 VQ-DNN이 나타내는 시간적 평활화로부터의 불확실성은 BNN에 나타난 불확실성과 다른 특징을 보임을 알 수 있습니다. VQ-BNN은 이 두 가지 종류의 불확실성을 동시에 포함하고 있습니다. 이 그림에 대한 상세한 설명은 논문의 Appendix D.2를 참고해 주시기 바랍니다.
